Project available on GitHub
Introduction
The World Air Quality Index project centralizes Air Quality Index (AQI) data from 2 000+ cities and 30 000+ stations across the world. It is a non-profit organization based in Beijing. It provides a completely free API to get both historical data and real-time data. Kudos to these guys!
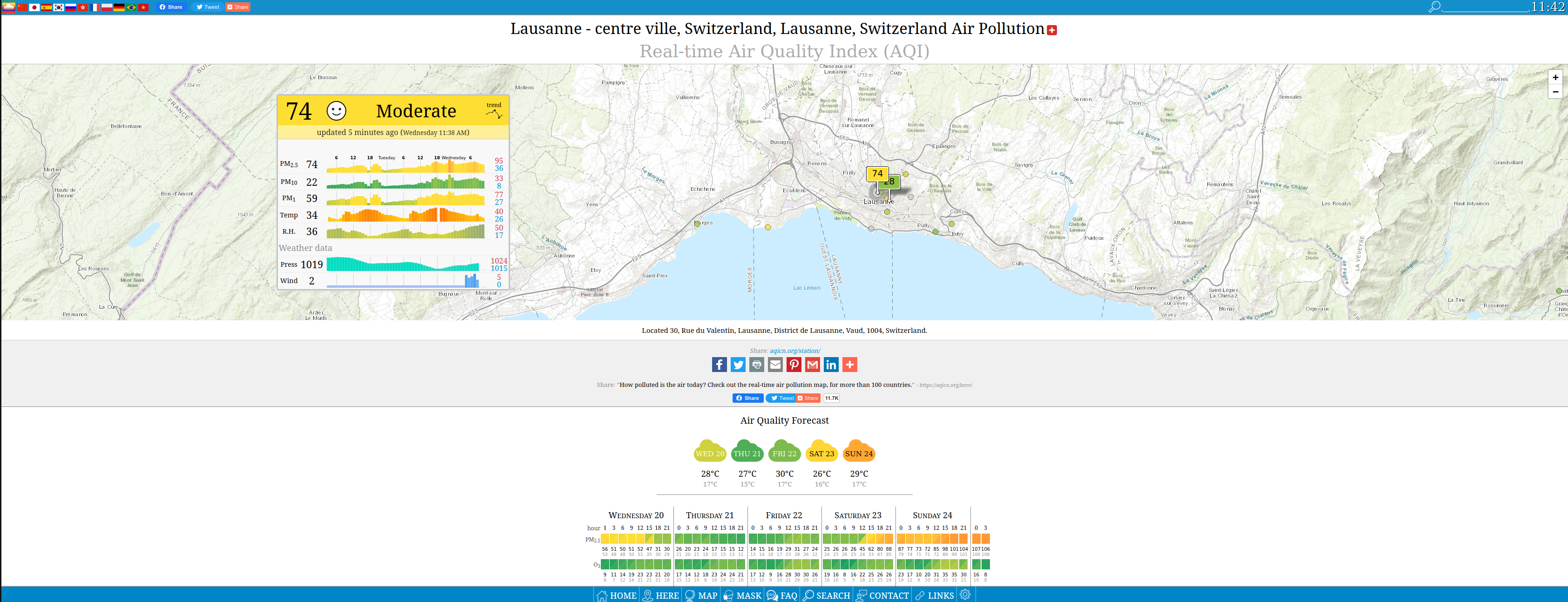
The project
We are going to build a real-time stream of the air quality index of 9 cities across Switzerland. Here’s how it works:
- Every n seconds, we request the latest AQI (Air Quality Index) for the listed stations
- If new data is found, then it is pushed to a Kafka cluster
- On the other side of the cluster, the data is consumed in real time
What could be the applications of such a pipeline?
- Kafka relies on distributed computing, this is one of the reasons why it is highly scalable. So, we could be monitoring thousands of stations for AQI
- A Kafka cluster can be fed independently by multiple data-producing entities (called producers), so we could very well fetch data from other sources (e.g. weather forecasts, traffic…) and gather everything in the cluster
- Finally, we could merge and process this continuous flow of data almost as if it was a standard database using ksqlDB. This dataset could be used for modeling purpose (e.g. forecasting) on a regular basis, say to re-train a model everyday and compute predictions.
The code
My project looks very much like what you will find in this tutorial to get started with Kafka in Python. In Kafka there is a complete separation between two kinds of entities:
- The producers which feed the Kafka cluster with data (messages)
- The consumers which pull data from the cluster
I’ve mainly worked on the producer.py script, implementing the HTTP requests to the World Air Quality Index project’s API. This is done using the requests module.
All the steps to run the project are explained in the repository. Please feel free to reach out if you have any question.
When executing the producer script, we can see the data is fetched:
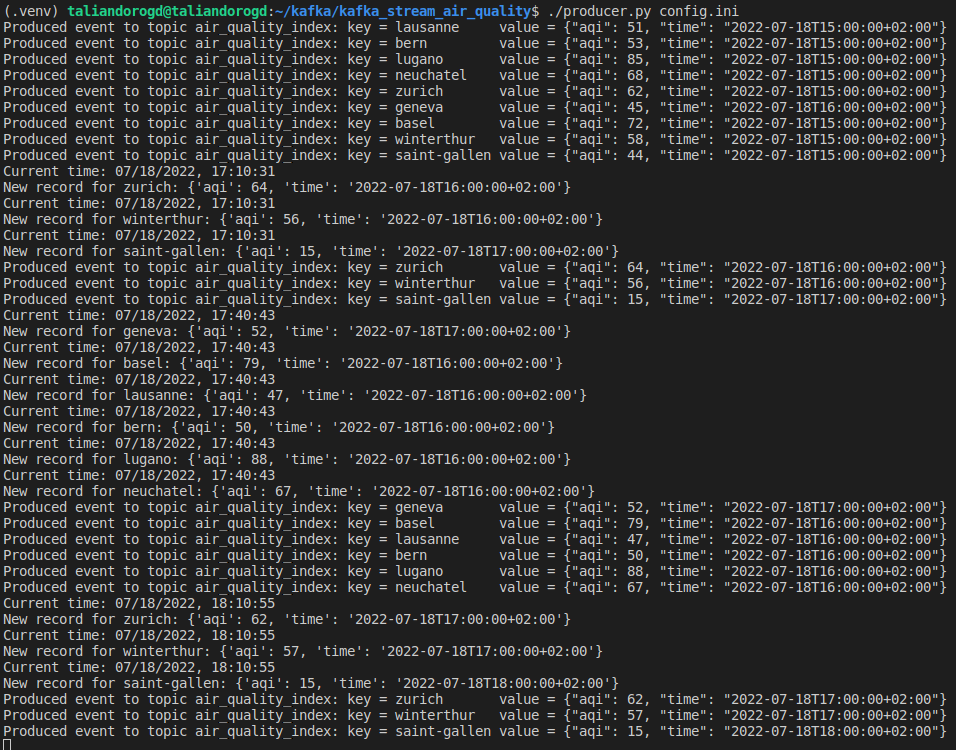
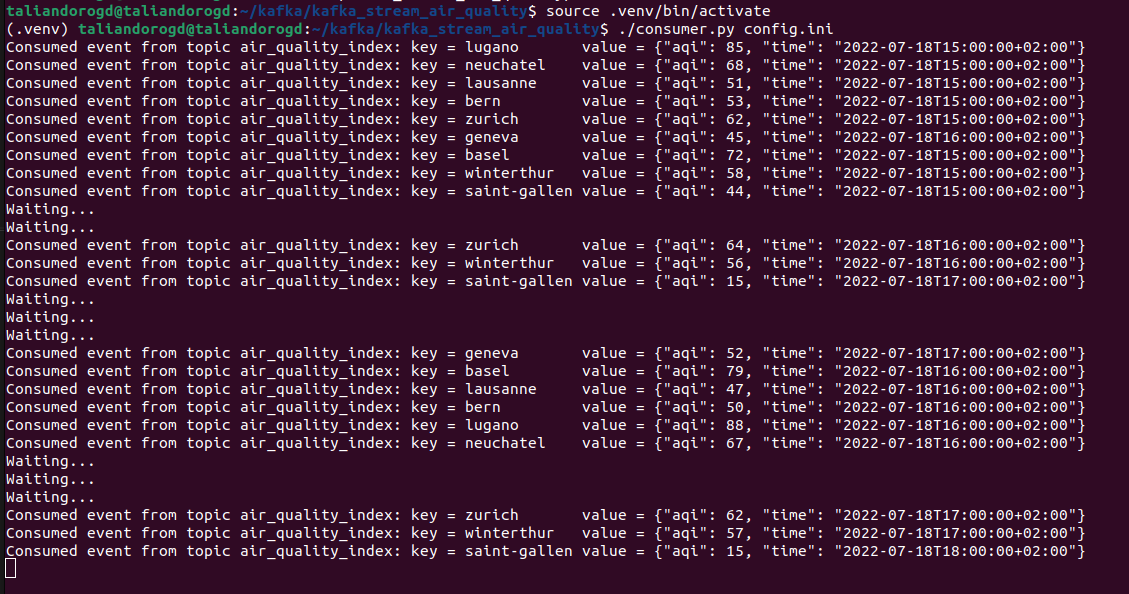
The data seems to be refreshed at most every hour, so we’re fine probing the server for new AQI measurements every 10 minutes. On the other side of the Kafka cluster, the consumer pulls the new records in real-time:
Next steps
Kafka is far for being a single tool, it actually consists in a myriad of systems and services. The next steps could be:
- to connect Kafka to a traditional database to store historical AQI data
- to implement a schema on top of the data to control its format
- to use ksqlDB to query the data, aggregating on a given time window for instance
Thanks for reading!