Full notebook available on GitHub
Text Classification: Transfer Learning vs Zero-Shot Classifier
🤗 Hugging Face is, in my opinion, one of the best things that has happened to Data Science over the past few years. From generalizing access to state-of-the-art NLP models with the transformers library to distillation [1], they are having a huge impact on the field. I recently found out about “Zero-Shot Classification”. These models are classifiers that do not need any fine-tuning, apart from being told which classes it should predict. They are built on top of Natural Language Inference models, whose task is determining if sentence A implies, contradicts or has nothing to do with sentence B. This excellent blog post written by 🤗 Hugging Face researcher Joe Davison provides more in-depth explanations.
Here is an example:
|
|

The classifier guessed that the sentence is about tech with a probability over 99%. But how does Zero-Shot classification compare with plain “old” fine-tuned text classification?
I) BBC News dataset
Let’s build a classifier of news articles labeled business, entertainment, politics, sport and tech. Available here, the dataset consists of 2225 documents from the BBC news website from the years 2004/2005. It was originally built for a Machine Learning paper about clustering [2].
Articles are individual .txt files spread into 5 folders, one for each folder. The listing below puts articles/labels into a pandas.DataFrame().
|
|
|
|

We will need integer labels to feed the transformer model:
|
|
Here are 5 random rows from the final dataframe:

II) Fine-tuning a pretrained text classifier
After building the train/validation/test sets, we will go straight the point by using the DistilBERT pre-trained transformer model (and its tokenizer).
It is a small, fast, cheap and light Transformer model trained by distilling BERT base. It has 40% less parameters than bert-base-uncased, runs 60% faster while preserving over 95% of BERT’s performances.
|
|
Tokenize
Loading DistilBERT’s tokenizer, we can see that this transformer model takes input sequences composed of up to 512 tokens:
|
|
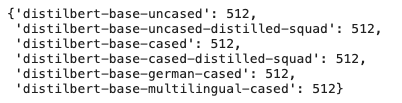
How does this compare with the lengths of the tokenized BBC articles?
|
|
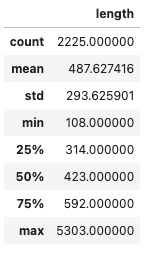
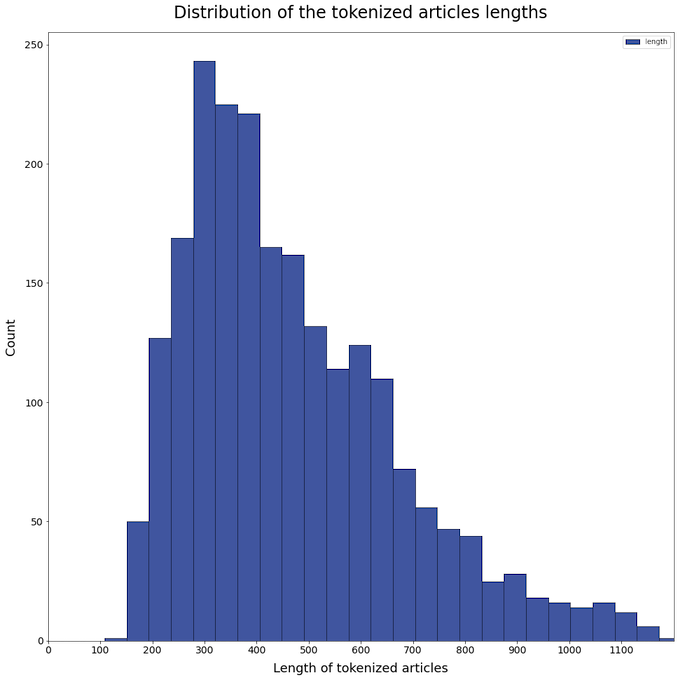
The articles are, on average, 488-token-long. The longest news is composed of 5303 tokens. This means that an important part of the articles will be truncated before being fed to the transformer model. Here is the distribution of the lengths:
|
|
|
|
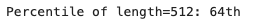
About 36% of the articles will be truncated to fit the 512-token limit of DistilBERT. The truncation is mandatory, otherwise the model crashes. We will use fixed padding for the sake of simplicity here.
Fine-tune DistilBERT
The train/validation/test sets must be procesμsed to work with either PyTorch or TensorFlow.
|
|
|
|
|
|
|
|
Accuracy
|
|
The accuracy of the fine-tuned DistilBERT transformer model on the test set is 98.65%.
Misclassified articles
There are only 3 errors on the test set, out of 56 articles. Besides, the misclassifications actually make sense because the articles could very well have been labelled differently:
- The first article was put into the category business by the labeller whereas the model predicted politics. But since it is about the richest countries’ ministers/presidents writing off some African countries’ debt, it is also definitely about politics
- The second article is about the censorship of a play in Uganda, so the predicted label politics could actually be deemed more relevant than the original label, entertainment
- The third misclassified article is about the impact of IT on UK’s firms, mainly through e-commerce, and the role of the government in this area. So politics (actual), tech (predicted) and even business are fine as labels
III) Zero-Shot Classification
We’ll use the appropriate transformers.pipeline to compute the predicted class for each article.
|
|
We end up with an accuracy of 58.74% with the Zero-Shot classifier.
So, this classifier does a really bad job compared with the fine-tuned model. However, given the number of labels — 5 — this result is not that catastrophic. It is well above the 20% a random classifier would achieve (assuming balanced classes). Glancing at a few random articles uncorrectly labeled by the Zero-Shot classifier, there does not seem to be a particularly problematic class, although such a assertion would require further investigation. But the length of the news could lead to poor performance. We can read about this on the 🤗 Hugging Face forum. Joe Davison, 🤗 Hugging Face developer and creator of the Zero-Shot pipeline, says the following:
For long documents, I don’t think there’s an ideal solution right now. If truncation isn’t satisfactory, then the best thing you can do is probably split the document into smaller segments and ensemble the scores somehow.
We’ll try another solution: summarizing the article first, then Zero-Shot classifying it.
IV) Summarization + Zero-Shot Classification
The easiest way to do this would have been to line up the SummarizationPipeline with the ZeroShotClassificationPipeline. This is not possible, at least with my version of the transformers library (3.5.1). The reason for this is that the SummarizationPipeline uses Facebook’s BART model, whose maximal input length is 1024 tokens. However, transformers’s tokenizers, including BartTokenizer, do not automatically truncate sequences to the max input length of the corresponding model. As a consequence, the SummarizationPipeline crashes whenever sequences longer than 1024 tokens are given as inputs. Since there are quite a few long articles in the BBC dataset, we will have to make a custom summarization pipeline that truncates news longers than 1024 tokens.
|
|
This time, the accuracy increases to 73.54%.
Adding the summarization before the zero-shot classification, the accuracy jumped by ~15%! Let us remember that there was no training whatsoever. From this perspective, a 73.5% accuracy looks pretty good. This result could probably be enhanced by tuning the summarizer’s parameters regarding beam search or maximal length.
V) Conclusion
Text classification is a piece of cake using 🤗 Hugging Face’s pre-trained models: fine-tuning DistilBERT is fast (using a GPU), easy and it resulted in a 98.65% accuracy on the BBC News test set. Although this result should be confirmed with other train-test split (only 56 articles in the test set), it is absolutely remarkable. The raw Zero-Shot Classification pipeline from the transformers library could not compete at all with such a performance, ending up with a ~59% accuracy on the same test set. Nonetheless, this result is still decent considering the complete absence of training required by this method.
Given the substantial length of the BBC News articles, we tried summarizing them before performing the Zero-Shot classification, still using the beloved transformers library. This method resulted in a +15% increase of accuracy. Another way would have been to carry out sentence segmentation before the Zero-Shot classification, and averaging the prediction over all an article’s sentences.
We end up with two text classifiers:
- One that requires training and yields a 98.65% accuracy
- One that does not require any training, but yields a ~73.5% accuracy
Long live 🤗 Hugging Face!
References
[1] Victor Sanh, Lysandre Debut, Julien Chaumond, Thomas Wolf. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. (Hugging Face, 2020)
[2] D. Greene and P. Cunningham. “Practical Solutions to the Problem of Diagonal Dominance in Kernel Document Clustering”, Proc. ICML 2006.