What is an outlier ?
An outlier can be defined as an observation that appears to deviate markedly from other members of the sample in which it occurs [1]. The question that immediately arises is the following: is this observation inconsistent ? Meaning was it generated by a different mechanism, or is it just “bad luck” ? This problem is kind of important, since as François Chollet (creator of the API Keras) recently tweeted:
All datasets have outliers. And your production data will always feature outliers of a kind never seen in your training data.
— François Chollet (@fchollet) August 21, 2020
Different ways to identify outliers
There are quite a few methods to study outliers and eventually detect anomalies. They can be classified in several ways. Some methods are global as opposed to local algorithms, which only use the $k \in \mathbb{N}$ nearest neighbors. Algorithms like DBSCAN [2] assign a binary label to observations (outlier or not) while others (Isolation Forest [3], Local Outlier Factor [4] or more recently Local Distance-based Outlier Factor [5]) output an anomaly score. Other criteria are to be considered depending on the use case: parametric or not, supervised or unsupervised, etc…
Local Outlier Factor
Today, we will focus mainly on a specific algorithm, namely Local Outlier Factor. In my opinions, this method is well adapted to real-world anomaly detection for several reasons. First, it is unsupervised, hence they do not require preliminary time-consuming - and possibly unreliable - work to characterize abnormal observations. Secondly, a list of individuals ranked by decreasing anomaly score can be generated with this methods. This is very a big advantage over binary algorithms because it allows the user to retain/inspect only a given number of observations, according to his time and need. Thirdly, Local Outlier Factor is distribution-free. This is crucial because estimating distribution can be very challenging, especially if the observations belong to a high-dimensional space (see the curse of dimensionality). Lastly, Local Outlier Factor is, well, local. This allows LOF to perform well in configurations like this one (code for this plot available in the R script):
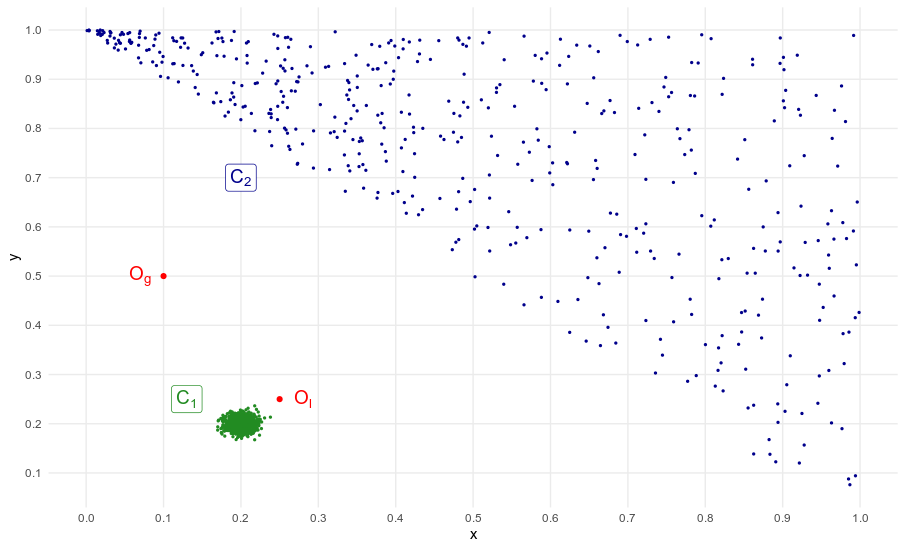
This dataset will be our case study.
So, why does it have to be local ?
In the example above, largely inspired from the original LOF paper [4], $C_1$/$C_2$ are cluster and $O_l$/$O_g$ are outliers. $O_l$ is considered a local outlier because the distance between $C_1$ and $O_l$ is not greater than say the average distance between $C_2$’s neighboring points. On the contrary, $O_g$ is clearly a global outlier. In this situation, a global anomaly detection method will most likely identify as outlier only $O_g$, or $O_g$, $O_l$ and a many observations from $C_2$. Only a local method will detect $O_g$ and $O_l$. This point is important because real-world data is often scattered, with several clusters of different densities.
The input parameter k
The LOF method is a k-nearest neighbors style algorithm [4], so it requires an integer $k$ as an input argument. Its creators were nice enough to give guidelines for choosing a set of appropriate values for the parameter $k$.
First, $k=10$ appears to be a reasonable lower bound. Indeed if $k < 10$, the authors have empirically observed that the standard deviation of LOF computed on observations from a 2D Gaussian sample is unstable, and that some observations from a 2D uniform distribution are clearly identified as outliers, which is problematic in this case. Alternatively, the lower bound for $k$ can be regarded as the minimal number of observations a set has to contain in order to be considered a cluster.
Secondly, the upper bound for k can be regarded as the highest number of outliers there can be relatively to a given cluster. In our case study, we only have two outliers so it is unnecessary to go well above 10. We decide to compute LOF for $10 \leq k \leq 15$. As the creators suggest, we will retain the maximum value i.e $\underset{10 \leq k \leq 15}{max} \ LOF_k(observation)$ for each observation.
Interpretation of the Local Outlier Factor
Let $C$ be a set of observations and $k$ the input parameter presented above. Then for all $p \in C$ such that the k-nearest neighbors of $p$ and their k-nearest neighbors also belong to $C$, the following inequality stands [4]: $$\frac{1}{1+\epsilon} \leq \ LOF_{Minpts}(p) \ \leq 1+\epsilon$$ where $\epsilon$ is a measure of $C$’s “looseness”. Hence if $C$ is a “tight” cluster, then the local outlier factor of all the observations that belong to $C$ is close to 1. On the contrary, the LOF of an outlier is well above 1.
LOF vs Isolation Forest: let the battle begin
Now, let us see how LOF performs on the dataset plotted above, and compare the results with the global method Isolation Forest. The results presented below were generated by the R script. The Python script gives very similar results, with fluctuations due to random number generation.
Dataset
First, let us generate the data. We use a normal distribution for $C_1$ and a uniform distribution for $C_2$, then we manually add the two outliers to the dataset. We also add an id column as a primary key for the observations.
Python
|
|
R
|
|
We get the dataset we already showed above, with two clusters, one global outlier and one local outlier.
LOF
Now let us begin the outlier detection process. As explained before, we compute the LOF of each observation for $10 \leq k \leq 15$, then we retain the maximal value.
Python
We use the beloved module scikit-learn.
|
|
R
We use the R package Rlof and the function rlof().
|
|
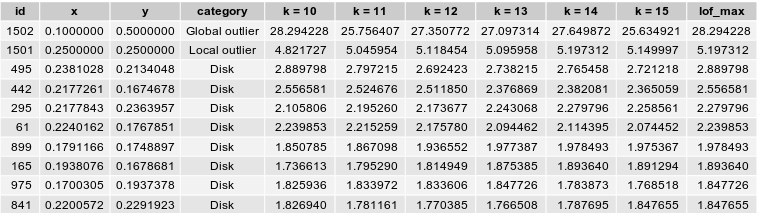
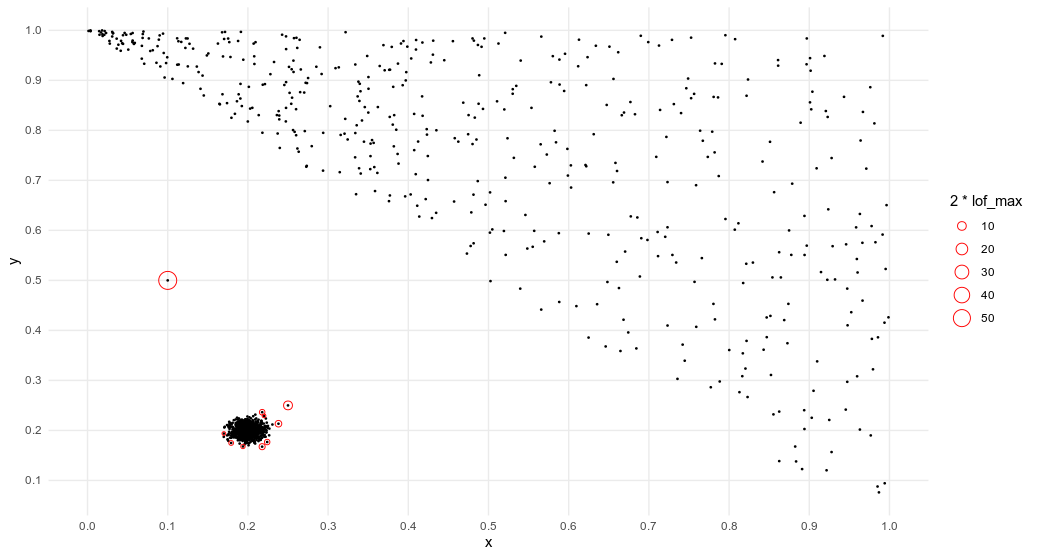
Success ! The Local Outlier Factor algorithm clearly identifies the two outliers of our datasets, as the anomaly score of the these points are the highest and well above 1. Below is a representation of the 10 observations with the highest LOF. They are circled with a radius proportional to their score.
Comparison with Isolation Forest
Python
|
|
R
We use the R package solitude.
|
|
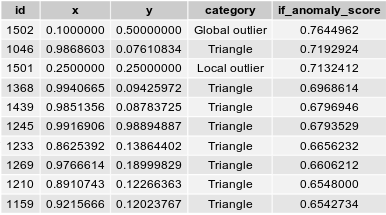
As a global anomaly detection, Isolation Forest clearly detects the outlier $O_g$. The anomaly score of this global outlier is the highest, and well above the second highest value. However, the Isolation Forest algorithm fails to distinctely identify the local outlier $O_l$. Even though its anomaly score is the third highest value of the dataset, it does not clearly stands out from the other anomaly scores.
Conclusion
In my experience, Local Outlier Factor is one of the best methods to identify outliers and detect anomalies. We have seen that it works very well on today’s case study, but it is efficient in many other configurations. Nonetheless, LOF is admittedly one of the anomaly detection algorithms that requires the most computing power, particularly when applied on big datasets. Other than that, the fact that it is unsupervised, distribution-free, local (so well-adapted to multiple clusters of different densities) and that it outputs a real number are the reasons why it is the way to go.
All the code can be found on my Github.
References
[1] BARNETT, V., LEWIS, T., Outliers in Statistical Data, 1994. 3rd edition, John Wiley & Sons.
[2] ESTER, Martin, KRIEGEL, Hans-Peter, SANDER, Jiirg, XU, Xiaowei: A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. Institute for Computer Science, University of Munich, 1996.
[3] LIU, Fei Tony, TING, Kai Ming and ZHOU, Zhi-Hua: Isolation forest. Data Mining, 2008. ICDM 2008. Eighth IEEE International Conference on Data Mining.
[4] Markus M. Breunig, Hans-Peter Kriegel, Raymond T. Ng, Jörg Sander, *LOF: Identifying Density-Based Local Outliers
[5] ZHANG, K., HUTTER, M., JIN, H., New Local Distance-Based Outlier Detection Approach for Scattered Real-World Data, 2009.