Introduction
The topic of the present post originates from the superconductivity dataset — available on the UCI Machine Learning Repository — and the associated paper [1]. The problem consists in predicting the critical temperature $T_c$ of superconductors. At or below this temperature, such a compound conducts current with zero resistance, hence eliminating power loss due to Joule heating. Surprisingly enough, the scientific community has failed to model $T_c$ since the discovery of superconductivity by Dutch physicist Heike Kamerlingh Onnes in 1911.

In his study [1], Kam Hamidieh builds a gradient boosted trees using the XGBoost algorithm. He ends up with an out-of-sample RMSE of 9.5 °K. Let us see how the LightGBM framework performs on this specific task.
Data
The dataset contains 21 263 superconductors described by 81 explanatory variables, and one more response variable $Tc$. We are cosily ensconced in the supervised learning framework, and more specifically, regression. The explanatory variables are all continuous and positive. They are related to the eight following physical properties of every atom forming the superconductor: atomic mass, first ionization energy, atomic radius, density, electron affinity, fusion heat, thermal conductivity and valence. For each of these characteristics, ten summary statistics are computed mean, weighted mean, geometric mean, entropy, range, etc… These quantities are the actual values of the independent variables. As a consequence, we get 8*10 = 80 highly correlated features. In this context, leaning towards tree-based ensemble methods seems reasonable. The eighty-first input variable is the number of atoms in the superconductor molecule.
|
|
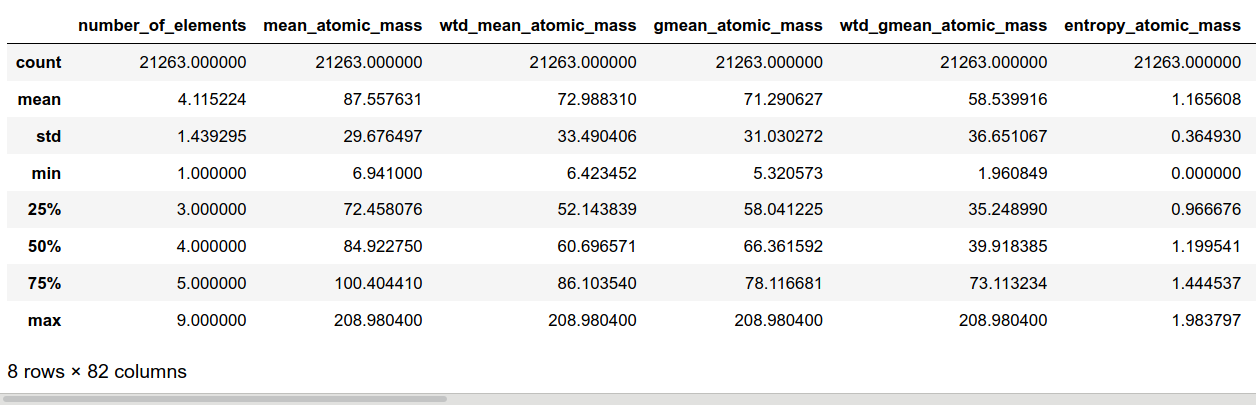
More information on data preparation, feature extraction as well as a descriptive analysis of the dataset are available in the original paper [1]. The following block attests that there are no missing values
|
|
XGBoost & LightGBM
XGBoost [2] and LightGBM [3] are slightly different implementations of gradient boosted trees. LightGBM is often considered as one as the fastest, most accurate and most efficient algorithm. The authors of the LightGBM documentation stress this point to a great extent. Although this may be correct in given situations, this Kaggle discussion shows that it depends on various parameters including the number of features, memory limitations, convergence and GPU vs CPU.
Let us see what happens with the superconductivity dataset. We will use the native Python API in both case to stay as objective as possible. Nonetheless, there are scikit-learn wrappers for both libraries. They are particularly useful with their integration to the sklearn.grid_search module.
Hardware
As my personal machine is getting quite old, the following computations were carried out in the cloud. We used a P4000 instance on Paperspace Gradient. We only used the CPU, although it is possible to use GPU both with LightGBM and XGBoost.
First test
In this part, we train a LightGBM model using the parameters provided by Kam Hamidieh in his paper. They were found with a grid search with cross-validation. We had to make a heavy use of LightGBM documentation to do an appropriate translation of these XGBoost parameters. To make an honest comparison with the original work, we use the same method to estimate the out-of-sample RMSE, that is:
- Split the data into random train and test subsets with 2/3 of the rows for training.
- Fit the model using the train data and compute the RMSE on the test sample.
- Repeat 25 times and retain the average RSME on the test data.
LightGBM
|
|

XGBoost
|
|

Using the same set of parameters in both libraries, LightGBM was approximately 12 times faster than XGBoost. However, the out-of-sample RMSE is 1.20 °K off in comparison with XGBoost’s performance.
A home-made grid search for appropriate LightGBM parameters
Let us try to improve the LightGBM model. Could we get lower RMSE and execution time than with XGBoost ? In this part, we do not dive into a meticulous grid search, but we implement an attempt based on the following recommendations from the LightGBM documentation to increase accuracy:
- Use large max_bin (may be slower)
- Use small learning_rate with large num_iterations
- Use large num_leaves (may cause over-fitting)
For each combination of all the other parameters, the number of iterations/trees i.e num_boost_round is selected through 5-fold cross-validation. In the end, we select the set of parameters that does best on the test sample.
|
|
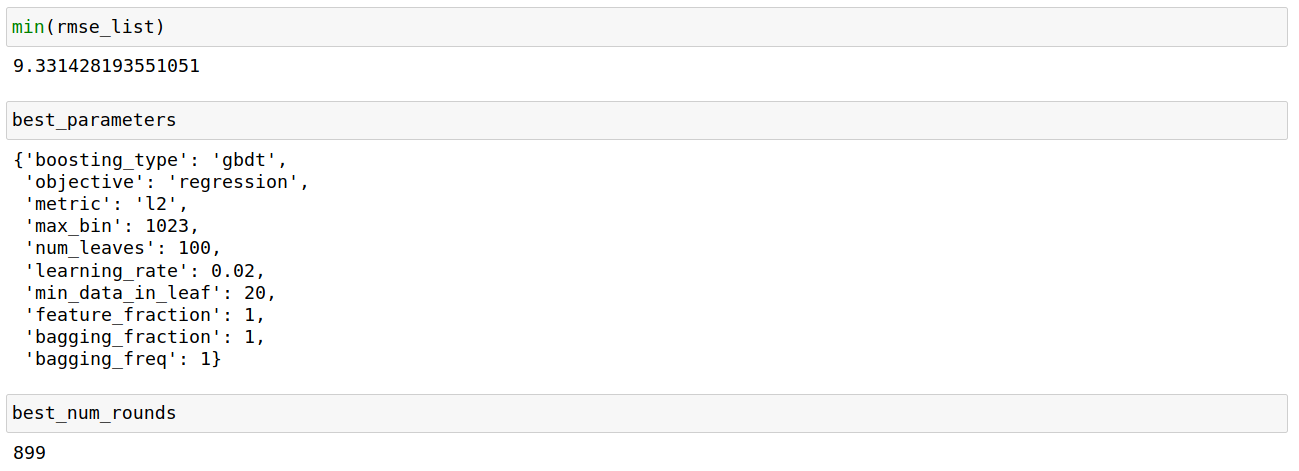
Again, we build this model 25 times on different random test-train splits (same code as in the “First test” part, but with best_parameters and best_num_rounds):

To give some perspective about this result, let us note that the standard deviation of the 25 RMSEs is approximately equal to 0.2. Their range is about 0.7.
Conclusion
In the end, our LightGBM model has achieved similar performance to XGBoost regarding both speed and accuracy. This does not mean that we could not reach better performance if we went deeper into hyperparameter tuning and grid searching. However, we can note that regarding this specific superconductivity problem/dataset, LightGBM did not trivially provided a better model than XGBoost. The source code of this experiment is entirely available on Github.
References
[1] HAMIDIEH, Kam A Data-Driven Statistical Model for Predicting the Critical Temperature of a Superconductor, University of Pennsylvania, Wharton, Statistics Department, 2018.
[2] CHEN, T., GUESTRIN, C. (2016). Xgboost: A scalable tree boosting system, University of Washington, 2016.
[3] Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, Tie-Yan Liu. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Advances in Neural Information Processing Systems 30 (NIPS 2017), pp. 3149-3157.